目前已开设游戏开发,大数据开发,影视后期全流程制作及游戏美术设计等课程,年培养优质人才近五百人,学生就业率高达97%,平均就业薪资6700元:让学生在技能培训中有机会参与更多公司的项目实战,通过企业订单,直达高端就业岗位。
秉承用良心做教育,让教育回归本质!
综合性数字技术研发培训机构

青岛ETL大数据培训课程,主要学习LINUX、HADOOP、HBASE、HIVE、SPOOP等课程内容,可从事ETL开发工程师、业务数据分析师、大数据分析工程师、大数据挖掘师、Spark工程师、建模数据挖掘师、Python开发工程师、数据产品经理等岗位。

主要学习LINUX、HADOOP、HBASE、HIVE、SPOOP等课程内容。政策支持、行业前景、人才紧缺、超高薪资,可从事ETL开发工程师、业务数据分析师、大数据分析工程师、大数据挖掘师、Spark工程师等岗位。
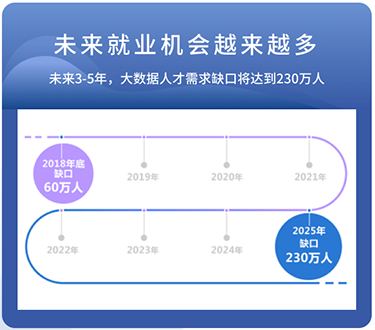
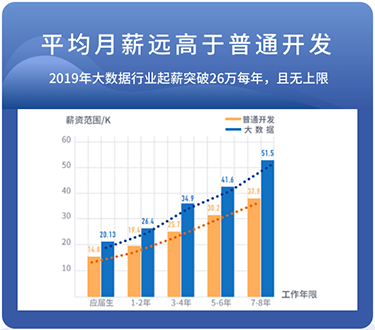


起点相同!能力不同!薪资悬殊!
数据仓库架构概述
数据仓库概述
数据库
混合型数据中心之大数据平台
混合型数据中心参考架构
ORACLE-SQL基础
数据库控制
数据库对象
ORACLE-PLSQL
SQL语言的基本结构 PLSQL高级编程
数据挖掘理论基础
数据的概念
数据的内容
数据属性及数据集
数据特征的统计描述 数据的可视化
数据相似与相异性的度量
数据质量
数据预处理
大数据ETL基础
从数据库到数据仓库 数据仓库的架构
数据仓库的数据模型 ETL技术
联机分析处理--OLAP OLAP的数据模型
大数据的加工与处理
抽取工具的特征 KETTLE的使用
数据挖掘的应用
数据挖掘的起源
数据挖掘的定义
数据挖掘的任务
数据挖掘标准流程
Linux
Linux系统详解
Linux系统进程
Linux启动流程
vi、vim编辑器
Linux用户和组账户管理
Linux磁盘管理
Linux系统文件权限管理
Linux的RPM软件包管理
yum 、Linux网络
Shell编程
Linux上常见软件的安装
Hadoop
Hadoop概述
HDFS
Mapreduce Mapreducer案例 Hadoop2.x集群
HBase
HBase与RDBMS的对比
数据模型
系统架构
HBase上的MapReduce
表的设计
集群的搭建过程讲解
集群的监控
集群的管理
HBase Shell以及演示
Hbase树形表设计 Hbase一对多和多对多表设计
Hbase微博案例
Hbase订单案例
Hbase表级优化Hbase数据读写优化
Hive
数据仓库基础知识Hive定义
Hive体系结构简介Hive集群
客户端简介
HiveQL定义
HiveQL与SQL的比较 数据类型
外部表和分区表
DDL与CLI客户端演示
Sqoop
配置和介绍Sqoop Sqoop shell使用 Sqoop- import DBMS- hdfs
DBMS- hive
DBMS- hbase Sqoop- export
Flume
flume简介-基础知识 flume安装与测试 flume部署方式 flume source相关配置及测试
flume sink相关配置及测试
flume selector 相关配置与案例分析 flume Sink Processors相关配置和案例分析
flume Interceptors相关配置和案例分析 flume AVRO Client开发
flume和kafka 的整合
Zookeeper
Zookeeper java API开发
Zookeeper RMI高可用分布式集群开发 Zookeeper REDIS高可用监控实现
NETTY异步IO通信框架
Zookeeper实现NRTTY分布式架构的高可用
Hue
Cloudera Hadoop Manager的分布式集群部署搭建
基于文件浏览器(File Browser)访问HDFS
基于Hive编辑器来开发和运行Hive查询
基于Solr进行搜索的应用,并提供可视化的数据视图,以及仪表板(Dashboard) 基于Impala的应用进行交互式查询
Spark编辑器和仪表板(Dashboard)
Oozie编辑器,可以通过仪表板提交和监控Workflow、Coordinator和Bundle
Python编程
介绍Python以及特点 Python的安装 Python基本操作(注释、逻辑、字符串使用等)
Python数据结构(元组、列表、字典) 使用Python进行批量重命名
Python常见内建函数 Python函数及使用常见技巧
Python异常的处理 Python函数的参数讲解
Scala编程
1. scala解释器、变量、常用数据类型等 2. scala的条件表达式、输入输出、循环等控制结构 3. scala的函数、默认参数、变长参数等 4. scala的数组、变长数组、多维数组等 5. scala的映射、元组等操作 6. scala的类,包括bean属性、辅助构造器、主构造器 7. scala的对象、单例对象、伴生对象、扩展类、apply方法
Spark-Score
Spark介绍
Spark应用场景 Spark和Hadoop MR、Storm的比较和优势
RDD Transformation Action、Spark计算PageRank
Lineage
Spark模型简介
Spark缓存策略和容错
处理宽依赖与窄依赖
Spark-Streaming
1Spark Streaming:数据源和DStream sparksql 编程实战 spark的多语言操作 spark新版本的新特性
Kafka
kafka是什么
kafka体系结构
kafka的存储策略 java编程操作kafka scala编程操作kafka flume和kafka的整合 Kafka和storm的整合
Storm
Storm的基本概念 Storm的应用场景 Storm集群搭建 Storm配置文件配置项讲解
集群搭建常见问题解决
Hadoop项目实战
项目实战一
项目实战二

数据仓库项目简介:整合各个业务线数据,为各个业务系统提供统一&规范的数据出口。是整个大数据系统中的关键,是所有数据分析、数据挖掘等工作的基础。
数仓项目开发流程:技术选型-数据采集-数仓设计-数仓开发-任务调度-项目优化。
项目性能指标:满足日增100T+数据处理;查询速度满足秒级查询。
项目收获:学习并掌握数据仓库的分层设计&数据仓库从0~1的构建过程。

热线监控项目简介:对整个监控系统的一个可视化数据大屏展示,分别体现出诉求业务总量,转办案件排名,资讯业务重量,来电资讯分类等数据进行分析。
数仓项目开发流程:技术选型-数据采集-数仓设计-数仓开发-任务调度-项目优化。
项目性能指标:满足日增100T+数据处理;查询速度满足秒级查询。
项目收获:学习并掌握数据仓库的分层设计&数据仓库从0~1的构建过程。

ETL开发讲师,ETL大数据工程师,4年Oracle数据库开发经验,3年EDW项目开发经验,3年大数据开发经验,曾任职海尔集团、印孚瑟斯技术(中国)有限公司等。
精通Oracle、PL/SQL、Mongodb等数据库,精通Informatica、Kettle工具的使用,精通Hadoop,HIVE,HBASE、Zookeeper、Kafka、Spark、Impala、Sqoop、Hue、Python等大数据以及数据分析技术,熟悉数据建模过程,对制造业、银行等行业IT应用方向具有一定经验。
参与并主导多个大数据项目:海尔集团EDW平台的整体建设,海尔集团多媒体客服中心大数据平台设计开发以及后期升级改造,1169用户中心大数据项目、四川移动大数据项目、山东农村信用社财报项目、潍坊银行微贷中心核算项目、海尔数据仓库EDW/TBM平台搭建项目等。

ETL讲师,大数据行业8年工作经验。
主要工作领域为金融大数据、医疗大数据、政府大数据。曾任职于北京文思海辉信息有限公司以及北京宇信科技有限公司。
作为项目经理和负责人完成过国家开发银行数据集市项目、苏州银行1104监管报送项目、浙江义乌商业银行数据平台项目。精通大数据可视化以及大数据云计算平台的架构和搭建,精通分布式计算的原理和架构,精通数据库运行机制以及ETL工具KETTLE/INFOMATICA的使用,精通大数据可视化平台帆软报表finereport的使用。精通ORACLE/DB2/SQLSERVER/PG等关系型数据库的使用,并能根据业务需求搭建合理的数据模型,开发全流程图形化界面以及B/S架构。

大数据ETL开发讲师,5年以上软件开发设计、系统架构、项目管理与实施经验。2年以上大数据相关开发经验,2年教学经验。
曾任职重庆中软国际开发事业部并参与多个政府项目的开发:重庆税务局税务系统、重庆税务局党建系统、
也担任过重庆文投大数据项目开发以及一些ERP系统的开发
精通各大主流框架如:spring、springmvc、mybatis、hibernate、springboot、springcloud等,熟悉各种主流开发管理工具:maven、svn、idea等,精通Hadoop,HIVE,HBASE、Zookeeper、Kafka、Python等大数据以及数据分析技术









与省内多家高校建立校企合作关系:专业共建、师资培养、课题申报、实验室建设等;与多家行业知名企业建立人才订单合作:青岛海信集团、天匠动画、甲壳虫动漫等。







